How to offload turbo decode to FPGA
This page describes the modification of OAI process to invoke Turbo offloaded to FPGA in the UE side L1 process (DLSCH).
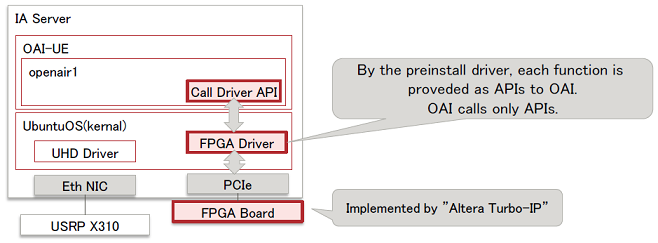
HW Accelerator with FPGA Board
Turbo Decoder on the UE side is offloaded to FPGA Board.

System Architecture
Specification of “PCIe FPGA Board”

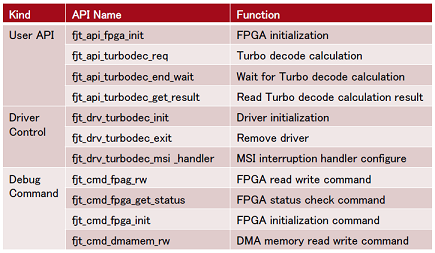
API List
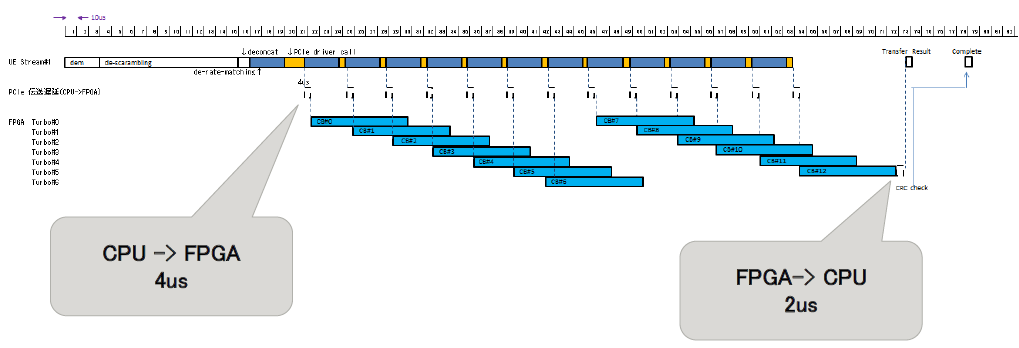
Timing chart and PCIe Transfer Delay
Performance Comparison
Turbo Decoding Time based on master branch 18.06.2016
befor offload : 400microsecond (phy total : 750microsecond)
after offload : 180microsecond (phy total : 510microsecond)
Totally it should be less than 1msec.
When you have 2CW, it might take 750x2us, which exeeds 1msec.
However when it's offloaded to FPGA, it takes only 510us, moreover the process can be executed simultaneously, so that the time dueration can be kept less than 1msec.
Modification image for the Turbo offload
Initialization
From OAI process, Turbo decode operation initialization API is called in order to use Turbo offload process in FPGA. The API call is located in the very beginning of main function described below. To be more concrete, API is called immediately after logInit.
Real : /targets/RT/USER/lte_softmodem.c main()
SIM : /openair1/SIMULATION/LTE_PHY/dlsim.c main()
DLSCH decode process (dlsch_decoding) In order to pass the data which the De-rate matching process is done to FPGA for Turbo offload, Turbo decode operation request API is called. When the API transfers the operation request to FPGA, the buffer mapped by Turbo decode operation initialization API is needed, but, this buffer transfer is done during 16bit -> 8bit conversion in Turbo decode operation request API,so that OAI has to give harq_process->w[r] to the API as it is (r is CodeBlock number).
After OAI calls Turbo decode operation request API as many as the number of CodeBlocks, OAI waits for the Turbo decode process completion by calling Turbo decode end wait API. The asynchronous mode is used for the API. The number of retry of the API call should be determined in case of no end response.
When the Turbo decode operation result read API returns NG or returns CRC NG, HARQ retransmission counter is incremented, and the function returns the iteration max number + 1. The API returns OK and CRC OK, OAI manages the pointer to the Turbo decoded data which is notified by the API. The buffer is stored in harq_process->b, and the function returns the iteration number which is also notified by the API.
The detailed process flow is described in the "Turbo Offload Modification Flow" sheet.
TurboOffloadModificationFlow.xlsx
OAI side sample source code : "turbo_decoder_offload" branch
For more information, please contact : yoshio.inoue@jp.fujitsu.com